
Big Data er det sidste link til forudsigelse af vejrforholdene. Rundt om i verden bruger tusinder af virksomheder, videnskabelige centre, institutioner osv. Big Data til at finde mønstre, uanset hvor de er, big data. I meteorologi, en videnskab, der også har en enorm og enorm mængde data, har Big Data også sine nyttige applikationer. Dette moderne og kraftfuldt værktøj, det kan bruges på flere måder. På trods af at det er navngivet som en enkelt ting, kan det opnå mange forskellige forudsigelser afhængigt af hvad du leder efter. Selvfølgelig er det også kommet til meteorologi, og her skal vi fortælle dig, hvad det gør, og hvordan.
Lad os først huske det foregribelse af tid har altid været et af de primære behov hos mennesker. For tusinder af år siden var vejrudsigter meget vigtige, endnu mere end i dag, for at overleve. Den teknologiske udvikling var ikke så banebrydende, enhver ustabilitet kunne få alvorlige konsekvenser. Selvom der altid var dette behov for at forhindre vejret, var det først med Aristoteles ankomst, at vi kan mønstre udtrykket meteorologi. Han kaldte det "meteorologisk", det navn, han gav sin bog, omkring 340 f.Kr.
Big Data i prognoser

Logikken med atmosfærisk adfærd er ikke stoppet med at udvikle sig siden da. Hver gang hurtigere. Går gennem det termometer, som Galileo opfandt i 1607, til computersimuleringer baseret på data indsamlet af satellitter. Lige nu står vi over for Big Data, mange er enige om det er det mest revolutionerende værktøj, siden Internettet findes og er ikke for mindre. Som om det var en science fiction-fremtid, kan vi i dag sige, at den er reel.
Som vi har kommenteret, begynder Big Data i dag at tage ansvaret for at give meteorologerne det andet synspunkt. Hvor de ikke kunne gå eller troede, at de havde ret uden at være, Store data viser dig, hvad der var skjult eller ubemærket, også med et niveau af præcision, der aldrig er nået. Der er virksomheder, der allerede tilbyder disse tjenester i dag. Institutioner, regeringer og virksomheder, der bruger store data til at foregribe klimaet. Men hvordan er hele denne proces? Hvordan gøres det? Hvordan drager vi fordel af det? Dernæst vil vi se og forstå, hvordan hele denne proces med teknologisk innovation er mulig.
Hvordan fungerer Big Data?
Rundt regnet, Big Data opgiver at se på himlen for at fokusere på data, og at de behandles korrekt. For at du mere kan forstå forståelsen af meteorologiens betydning, er det først nødvendigt at forklare, hvordan det fungerer.

Big Data har sin kernekraft i det, der kaldes 4 V'erne.
Volumen
Dette betyder mængden af data. Al denne mængde data indsamlet er det, der kaldes lydstyrken. Det kan variere afhængigt af, hvad der anvendes, nogle gange har vi mange data og andre gange "mindre". Det vil sige, vi kan gå fra 1.000 millioner data til flere billioner, afhængigt af hvilken der analyseres.
Hastighed
Jeg mener den hastighed, hvormed dataene genereres. De kommer fra behovet for at fange, gemme og behandle dem. Jo flere datafangster der er, jo hurtigere lagres de, jo mere er der at analysere. Hastighed er dobbelt vigtig i vejrudsigterne, da begivenheder opstår i realtid og skal behandles så hurtigt som muligt.
række
Nogle gange er der et format på, hvordan dataene kommer, andre gange andre. Hver type data har sin egen klassificering. Andre gange mangler nogle (der er teknikker til at løse dette, ellers ville fejlene være enorme), og andre gange kommer de i videoformer endda. Der er en meget forskellig datamasse, som i Big Data har ansvaret for at placere en ordre, en logik, der skal analyseres godt. For eksempel kan temperaturmålinger fra et termometer "ikke" placeres i samme pakke som satellitmålinger fra fronten.
Ægthed
Relateret til parentesen i det foregående punkt. Det betyder, at dataene endelig bliver reneuden "underlige" ting. Big Data management teams skal have et upartisk team, der er uddannet til at opretholde en god struktur. Konsekvenserne af en dårlig sandhed af dataene har meget negative virkninger. For at få en idé ville det være som om en gruppe mekanikere havde afsluttet reparationen af en bil, og de glemte at skrue to hjul.

Eksempel på rigtigheden af dataene
Vi har mange poster fra mange områder. Lad os forestille os, at vi har temperaturer, fugtighedsniveauer, vind osv. Men vi har en fejl, og vi mangler nogle temperaturregistreringer for et eller andet område, uanset årsag, og vi kan ikke få adgang til at vide, hvilken temperatur der er registreret. Vi har i alt 30 data, og to af dem uden temperatur endelig.
Hvad der f.eks. Kunne gøres, er at beregne gennemsnitstemperaturen i disse regioner for at bestemme nøjagtigt den mulige temperatur, der kan regnes med i den manglende post, men også med meget små fejlmarginer. Værdier er reservedele, og derefter kan beregningen omsættes i praksis. Havde disse data manglet, ville computerne ikke have genkendt det, skaber et sort hul i dataene og helt forkerte forudsigelser.
Hvordan får du det?
I meteorologi, som i ethvert felt, dataene kommer i form af variabler. Det vil sige, hver enkelt behandles på den måde, den hører hjemme. Og selvom det virker meget indviklet og kompliceret, bliver opgaven "let" for Big Data-analytikere. De variabler, som vi kan registrere i meteorologi, selvom de stadig er data, de kan tilhøre forskellige familier. Det vil sige, at en variabel er alle data, der kan klassificeres, men de er ikke altid de samme.
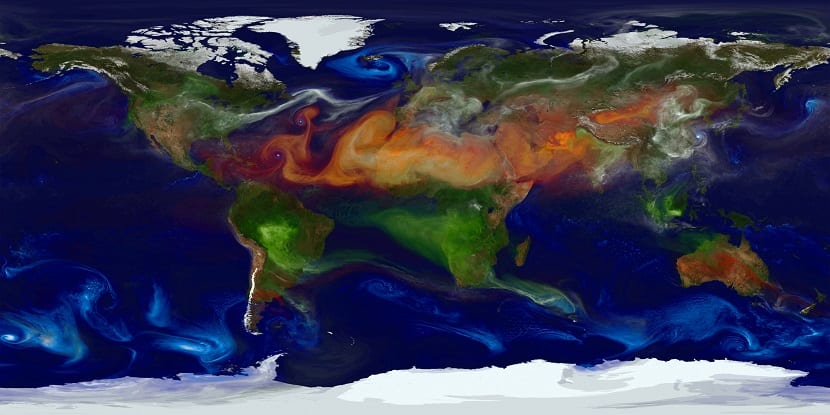
Billedet ovenfor, leveret af NASA, viser eksempel på strømme rundt om planeten. I tilfælde af NASA har de et stort antal satellitter, der giver dem mulighed for at observere og måle fænomener rundt om i verden i realtid.
Big Data kan læse alle spor, som noget efterlader om noget, og det kan betragtes som data. Mange, når de tænker på Big Data, vil hurtigt tænke over, hvornår vi bruger mobiltelefoner, surfer på internettet, klikker på en side, køber en vare online eller "kan lide" den på Facebook. Det er kun en "lille" men tæt del, ja, den er meget pålidelig og godt kodet. Men til gengæld efterlader vi et fysisk / virtuelt spor, som GPS-placeringen af, hvor vi er, takket være mobiltelefoner. Her begynder vi allerede at blande den virtuelle verden med den fysiske. Og selvfølgelig fysiske bevægelser, fysiske indkøb i henhold til alder, hvad vi vælger, alt dette arkiveres altid, og selvfølgelig kan det oversætte til flere og flere data.
Variabler kan være kategoriske
Kategoriske variabler er dem, der repræsenterer begrænsede værdier eller variabler, der ikke nødvendigvis betyder en bestemt størrelse. De repræsenterer kvaliteten af noget, de beskriver. Dybest set er deres specificitet begrænsningen af, hvad de repræsenterer. De kan klassificeres i to felter.
Nominelle kategoriske variabler
Det er de der repræsenterer ting i det samme felt uden en logisk forbindelse hver. For eksempel: Navnet på de regioner, der angiver, hvor posterne er fra, såsom byen, det autonome samfund, et postnummer osv.
Ordinære kategoriske variabler
Det er de der kan repræsentere størrelsen af noget, såsom Douglas-skalaen i bølgeniveauet, niveauet på skalaen, hvormed tornadoer kan klassificeres efter deres størrelse osv.

Variabler kan være numeriske
Numeriske variabler er de, der repræsenterer værdier eller variabler inden for en størrelse og kan måles. De repræsenterer kvantitative værdier. Deres særlige er, at de kan repræsentere et meget stort udvalg af målinger i meteorologiske fænomener. De er klassificeret på to måder
Kontinuerlige numeriske variabler
Kontinuerlige variabler er dem, der har ansvaret for at måle noget etableret. Eksempler på dem ville være fugtighedsindeks, temperatur, vindhastighed, regnmængde osv.
Diskrete numeriske variabler
Disse er dem de holder styr på noget etableret. Det vil sige antallet af gange det har regnet i et år i en region, antallet af gange det har sneet osv.
Alle variabler behandles
Når alle variabler er blevet klassificeret, behandles de takket være computere, altid under opsyn af analytikere af Big Data. Indtil for få år siden var mængden af data, der var tilgængelig, på trods af at det var et meget stort antal, ingen problemer, der skulle analyseres af dataanalytikere. Big Data-analyse er dog ansvarlig for analysen af disse massive data, hvor de analyseprocesser, der har været almindelige indtil i dag, ville tage lang tid (vi taler endda om dage) for at give et svar. Ikke kun det, Big Data er mere effektiv og nøjagtig ved at "spille" med variablerne imellem dem.

Alt dette stammer fra hvad vi tidligere har kommenteret på 4 V's Big Data, hvilket opnår hastighed, pålidelighed og vejrmodeller, der giver utroligt nøjagtige prognoser i en super kort periode.
Big Data som en spirende disciplin
Et godt eksempel ville være at tale om virksomheden ACCIONA, som har en Kontrolcenter for vedvarende energi (CECOER). Det er det største centrum i verden hvor målet er at levere løsninger i realtid af de millioner af data, der indsamles fra dets faciliteter, både biomasse, vind- og solenergi. Det producerer omkring 3000 årlige tidsplaner, der tager alle disse data for at tilpasse sig den krævede efterspørgsel. En anden fordel ved CECOER er modtagelsen af hændelser, de har fra deres faciliteter, så 50% af dem løses eksternt. De resterende 50% er fysisk fastsat af operatørerne. På denne måde Acciona får sin vedvarende energi, mere end at være en alternativ energi, er i dag en løsning.

CECOER-AKTION
En anden vigtig kendsgerning om Big Data i dag er manglen på dataforskere. Det er et spirende felt, og det har kørt op mod visse foruddefinerede standarder. Kan Big Data virkelig hjælpe så meget i udviklingen af prognoser, rapportere fordele til virksomheder, være i stand til at foregribe så mange ting og retfærdiggøre omkostningerne ved big data-analyse? Ja, men det er noget, der er set lidt efter lidt. Den voksende efterspørgsel efter dataforskere har parallelt med resultaterne og ved at forstå behovet for dem alle steder. Det er rigtigt, at der allerede er mange Big Data-teams, der arbejder med spektakulære resultater, men det er lige nu, hvor vi finder ud af, at der er en større efterspørgsel. Big Data-analytikere er meget efterspurgte.
Følgelig vi lever den revolution, som de indebærer i udvikling, men fra begyndelsen. Som enhver industri er vi nu vidne til dets potentiale, men det er ikke fuldt udviklet, det er noget, tiden har i vente for os. Den ene ting er allerede tydelig, dens nuværende potentiale, den anden, hvor langt den kan gå. Dine resultater vil ikke efterlade os ligeglade.

IBM-modelkort
IBMs The Weather Company er et privat firma, der tilbyder op til 26 millioner daglige prognoser om vejret. IBM har fra starten, også sammen med Google, skilt sig ud for at være en af de mest banebrydende virksomheder inden for området. Weather Company er yderst engageret i at hjælpe folk med at træffe informerede beslutninger om vejret. Det er det største netværk i verden fra personlige vejrstationer. Verdens største brands inden for luftfart, energi, forsikring, medier og regering er afhængige af The Weather Company for data, teknologiplatforme og tjenester.
Store data mod klimaændringer
FN's globale puls, et big data-initiativ fra FN og Western Digital Corporation, har underskrevet en alliance for at kæmpe sammen mod klimaændringer. Dette projekt ledet af FN og Western Digital Corp., samle forskere fra digital innovation fra hele verden at angribe problemet på en mere effektiv måde. Blandt dem finder vi samarbejdspartnere fra meget forskellige sektorer blandt dem. BBVA, Orange, Planet, Plume Labs, Nielsen, Schneider Electric, Waze ... er nogle af dem, der deltager i dette projekt.
Vi finder også Barcelona Supercomputing Center (BSC), Det er den 4. model i MareNostrum-serien. En supercomputer til Big Data-analyse nøgle inden for mange områder, blandt dem er også kampen for klimaændringer. Det blev taget i brug i slutningen af juni i 2017. Det er den tredje hurtigste computer i Europa, er der investeret i det til dets installation af 34 millioner euro af ministeriet for økonomi, industri og konkurrenceevne i Spanien. Den har en kapacitet på 14 petabyte, det vil sige 14 millioner gigabyte. Det når 11,1 Petaflops, det vil sige barbariteten på 11.100 milliarder operationer pr. Sekund.
Big Data i fremtiden for meteorologi og i vores liv
I en verden i forandring, hvor ændringer bliver hurtigere og stadig mere overraskende, er det vanskeligt at forudsige fremtiden for noget. Det vi ved med sikkerhed er, at Big Data er kommet for at blive, og at prognoserne både meteorologiske og andre områder efterlader os forvirrede. Nogle vil forblive skeptiske, andre vil benægte det, andre vil se det som noget langt væk. Men sandheden er, vi lever allerede med det.
I dag ved vi, at Big Data forventer mange regn, orkansæsoner og endda med stor præcision antallet af medaljer, som et land kan vinde i de olympiske lege. Den forudser også, hvem, hvor og hvornår en forbrydelse skal begås (hvis nogen har set "Minority Report" -filmen, er det gået i hjernen, ikke?). Store data bevæger sig hurtigt mod at foregribe fremtiden for mange områder, og det er, at selv Amazon begynder at foregribe det, og for nylig er det begyndt at foretage forsendelser, selv før kunderne foretager køb. Fremtiden var indtil i dag, ofte usikker. Men det ændrer sig fremtiden er forudsigelig.

Vi ved, at dets potentiale vil vokse. Hvem ved, det kan være udslæt at foregribe, hvem der forventer (Big Data) noget. Men med nok data, Vil Big Data være i stand til at foregribe det globale klima med enorm forventning? Ja. Ligesom du kan forudse, at vores handlinger ville give forskellige scenarier til de tidligere givne, fordi enhver handling har sit ekko i fremtiden, og Big Data kender det og evaluerer det igen, hvilket giver et andet nyt scenario.
Alt kan forventes. Vil vi være i stand til at vide i den nærmeste fremtid, hvad der vil ske med os? Hvilke problemer står vi over for? Hvornår og hvor rammer en orkan? Hvad skal vi for at fortsætte med at løse det? Efterhånden som teknikker forbedres, forbedres computere i effektivitet og hastighed, dette felt fortsætter med at udvikle sig ... Mest sandsynligt er, at snarere end at svare "hvem ved", er måske den mest passende ting at sige "lad os spørge Big Data".
BA-partnere | Willis-opdatering | GRYDE